
Genealogy and GEDCOM as a Network Exploration Facility
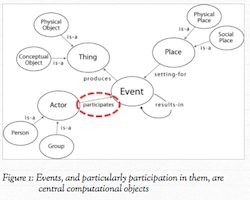
Nicholas Jenkins, in the Kindred Britain project, began his data excursion using the GEDCOM format and the OpenSource genealogical platform PHPGEDView. A logical and appropriate choice. He was working with individuals and was interested in their interrelations.